There is a short window after an interesting systems paper appears where almost nothing exists around it yet.
No polished blog posts. No long Hacker News thread. No popular GitHub repository. No settled opinion on whether the idea is important, niche, practical, or just clever.
Just the paper, the claims, and one tempting question:
Could I build something from this before the internet had finished reacting?
A few days ago, I found a new arXiv paper titled “Converting an Integer to a Decimal String in Under Two Nanoseconds” by Jael Champagne Gareau and Daniel Lemire.
That title immediately got me.
Integer-to-string conversion sounds like plumbing. It is the kind of operation you assume was solved long ago somewhere inside a standard library. But it sits underneath logging, JSON serialization, CSV export, databases, telemetry, benchmarks, and almost every system that eventually needs to turn numbers into text.
Small operations become interesting when they happen everywhere.

Why this paper caught my attention
One of the authors was Daniel Lemire, whose work I already knew through simdjson.
I had previously written about JSON parsing benchmarks, so this felt close to something I already cared about: performance work that looks boring from the outside but becomes fascinating once you look at the hardware details.
I also have a soft spot for silly benchmarks.
Not because they are always useful on their own, but because they force you to care about things you normally ignore: CPU features, compiler behavior, branch prediction, memory layout, vectorization, and whether your “simple” code is actually simple for the machine.
So when I saw a fresh paper about integer formatting in under two nanoseconds, my first reaction was:
That sounds unreasonable. I want to try it.
But the timing mattered too.
The paper still felt early. There was not yet a big public conversation around it. There was code associated with the paper, so this was not about pretending the algorithm was mine. It was not.
The question I was interested in was slightly different:
Could I turn the idea into a small, understandable C++ library while the paper was still fresh?
The repo existed before it deserved to
I searched around for existing projects, discussions, and obvious repository names.
Then I checked whether simditoa was available.
It was.
That was the moment the project became real enough to be dangerous.
Creating a GitHub repository is almost too easy. You pick a name, click a button, and suddenly there is a public place on the internet that implies something exists.
Even an empty repo has a promise attached to it.
simditoa felt like the right name: short, specific, and in the same naming family as projects like simdjson and simdutf.
So I created the repository.
At that point, the repo existed before it had earned the name.
The rest of the work was trying to make it catch up.
Starting with the shape, not the code
Before writing much of the implementation, I cloned simdjson and simdutf.
Not to copy the algorithms, but to study the shape of serious C++ projects.
A mature open-source project has a texture before you even read the core implementation. You can see it in the boring files:
- the public headers
- the source layout
- the CMake setup
- the tests
- the benchmarks
- the README
- the license
- the install story
- the fallback behavior
- the way CPU-specific code is explained
That was the part I wanted to get right.
I did not want a folder full of code that happened to compile. I wanted something that looked and behaved like a small C++ library someone else could inspect, build, test, and question.
So I scaffolded the project first: README, license, CMake, public headers, source layout, tests, benchmarks, and contribution notes.
The boring files mattered because they changed the project from “some code I wrote after reading a paper” into something closer to a usable artifact.
Using coding agents without letting speed decide everything
I used OpenAI Codex and GitHub Copilot while building the project.
That helped a lot.
It also made it very easy to produce something that only looked legitimate.
I could have pasted the paper into a coding agent, asked it to generate a C++ library, pushed the result, and ended up with a README, a benchmark table, a CMake file, and just enough code to make the repository appear real.
That was exactly what I wanted to avoid.
So I tried to keep the agents boxed in.
Before asking for implementation help, I defined the project boundaries myself:
- What should the public API look like?
- What should be internal?
- What should happen on machines without AVX-512?
- What should the benchmark compare against?
- What should the README claim?
- What should it avoid claiming?
Then I gave the agents narrow tasks.
One task for scaffolding. One for tests. One for CMake cleanup. One for the scalar path. One for benchmark structure. One for reviewing specific implementation details.
The most useful part was not that the agents wrote code quickly. It was that they helped me keep momentum while I stayed focused on direction, review, and boundaries.
The faster the tooling made implementation feel, the more important it became to slow down around the claims.
Especially the benchmark claims.
What simditoa actually does
At a high level, simditoa is a small C++ library for converting integers into decimal strings.
It exposes a to_chars-style API:
#include "simditoa.h"
char buf[simditoa::MAX_DIGITS + 1];
size_t len = simditoa::to_chars(12345, buf);
buf[len] = '\0';The current version supports signed and unsigned 64-bit integers, uses AVX-512 IFMA + VBMI on supported x86-64 CPUs, and falls back to a scalar implementation elsewhere.
The interesting part of the paper is that it does not treat integer formatting as a simple digit-at-a-time division loop. Instead, it uses SIMD instructions and precomputed constants to extract decimal digits in parallel.
That is what made the idea fun to explore.
It takes one of the most ordinary operations in programming and turns it into a hardware-aware algorithm.
Benchmarking: where the headline met reality
The paper title says under two nanoseconds.
My project did not magically hit that number.
To test it properly, I spun up an AWS VM with support for AVX-512 IFMA + VBMI and ran benchmarks against my baseline.
I did not reproduce the paper’s headline result, but I did see a meaningful improvement. In my benchmark run, simditoa was roughly 2x faster than the baseline implementation I tested.
That result was encouraging, but it needed restraint.
It does not mean the library is faster on every machine. It does not mean it beats every standard library implementation. It does not mean every workload will benefit. It does not mean I reproduced the full paper.
It means that, on the hardware I tested, this small implementation showed enough promise to be worth sharing.
That distinction matters.
A benchmark is not decoration for a README. It is a public claim with numbers attached. As soon as you publish it, people are allowed to ask uncomfortable but necessary questions:
Which compiler? Which standard library? Which flags? Which CPU? Which input distribution? Single values or batches? Was the output actually used?
If the benchmark is honest, those questions make the project better.
Posting it to /r/cpp
Once the project felt presentable, I wanted to share it with people who might actually care.
My first thought was /r/programming, but the rules made it clear that it was not the right place for a personal project.
That was probably a good thing.
simditoa is narrow. It is C++-specific, CPU-specific, benchmark-heavy, and based on a systems paper. A general programming audience might have produced more traffic, but /r/cpp was more likely to produce useful scrutiny.
So I drafted a short post.
I included the project link, the paper link, the basic API, what the library supported, the benchmark result, and a clear note that this was not a full reproduction of every result in the paper.
I posted around 3pm CET, partly because that gave the post a chance to overlap with daytime in the US.
That feels slightly embarrassing to admit, but it is part of publishing technical work.
Writing the code is one thing. Giving the right people a chance to see it is another.
Almost 24 hours later, the post had reached around 137+ upvotes, 25K views, a few comments, and a noticeable bump in GitHub stars.
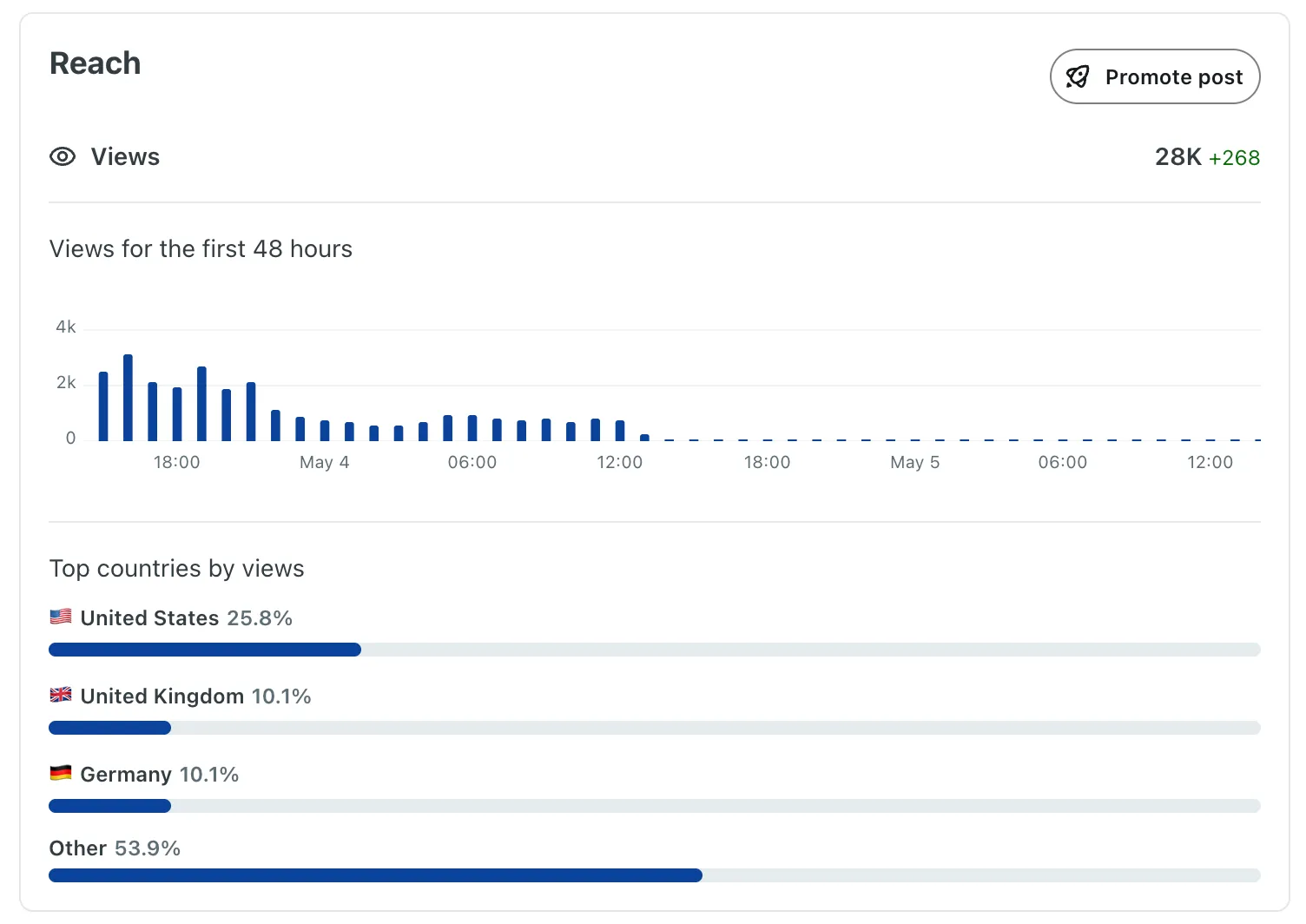
The numbers were not the point, but they were a signal that the project reached the right room.
The useful discomfort of feedback
The best part of posting to a specialized community is also the uncomfortable part.
People do not just clap.
They ask what you measured.
One of the first useful questions was about which std::to_chars implementation I benchmarked against. Others asked whether the speedup applied to individual conversions or only batches, and whether something similar could work with WebAssembly SIMD.
That was exactly the kind of feedback I wanted.
A generic audience might focus on the headline. A C++ audience starts pulling on the claims.
That can be uncomfortable, but it is also the point.
A private benchmark can stay vague. A public benchmark has to grow up.
The failed attempt before this one
A few days before starting simditoa, I tried to help another researcher fix a bug in a Rust project.
It did not go especially well.
I moved too quickly, missed context, and my approach was not sound enough. The researcher eventually fixed the issue themselves, and they were kind enough to acknowledge my attempt.
That experience was still fresh when I started this project.
It made me more cautious.
Not slower exactly, but more aware of the difference between making changes and understanding the problem.
With simditoa, I tried to approach things differently. I spent more time studying the surrounding project shape. I kept the paper’s contribution separate from my implementation. I reviewed early changes more critically. I tried to keep the README honest about what the project was and was not.
That previous failure probably made this project better.
It also made the whole thing feel less like a clean success story, which is probably more accurate.
What I learned from catching a paper early
Trying to catch a systems paper before the internet does is strange.
You are working in a temporary vacuum.
There are fewer blog posts to lean on. Fewer implementations to compare against. Fewer public opinions telling you whether the idea matters.
That makes it exciting, but it also removes excuses.
You have to read carefully. You have to claim less. You have to benchmark honestly. You have to explain what came from the paper and what you added around it. You have to publish before you feel fully ready.
simditoa started as a small bet that this paper was worth paying attention to.
The code was part of that bet, but not all of it.
The rest was the surrounding work: naming the project, shaping the API, writing the README, setting up the build, running the benchmark, choosing the right community, answering questions, and being careful not to overstate the result.
I do not know whether simditoa will become useful beyond this experiment.
That is fine.
It already did something useful for me: it forced me to move from passive interest to public artifact while the idea was still fresh.
That small window after a paper appears is uncomfortable.
I think that is why I enjoyed it.